




















Если ваш проект подразумевает генерацию одного персонажа в разном окружении, а не рандомного, то эта статья для вас
Мы будем использовать в качестве примера портреты, но эта техника будет работать с мультфильмами, предметами, иллюстрациями, с чем угодно. Имейте в виду, что это всего лишь один из способов решить эту задачу
Начнем с того, что мы знаем
Midjourney – это диффузионная модель ИИ 1, она создает изображения из шума, используя письменные подсказки (описания) того, что вы хотите, чтобы нейросеть сгенерировала.
Когда дело доходит до тонкой настройки или обучения вашей собственной модели, Midjourney не похож на Stable Diffusion 2. Вы не можете обучить модель в Midjourney и использовать ее для конкретных нужд.
Со Stable Diffusion создание последовательных (похожих) персонажей намного проще. Но мы здесь, чтобы посмотреть, что можно сделать с Midjourney.
В Midjourney можно использовать то, что называется «изображение-подсказка» (image prompting). Это метод, при котором мы используем изображения в качестве референса в наших запросах. Это не обучение Midjourney как таковое, а скорее работает как несколько подсказок в ChatGPT, вы можете намекнуть на что-то, что хотите, или на стиль, и Midjourney использует это как «вдохновение» при создании генераций.

Чтобы изображение-подсказка работало, вам нужны ссылки на изображения, или если изображение загружено в Discord 3. Чтобы загрузить изображения в Discord, вам просто нужно отправить их туда в сообщении, скопировать URL-адреса и вставить в строку-промпт.
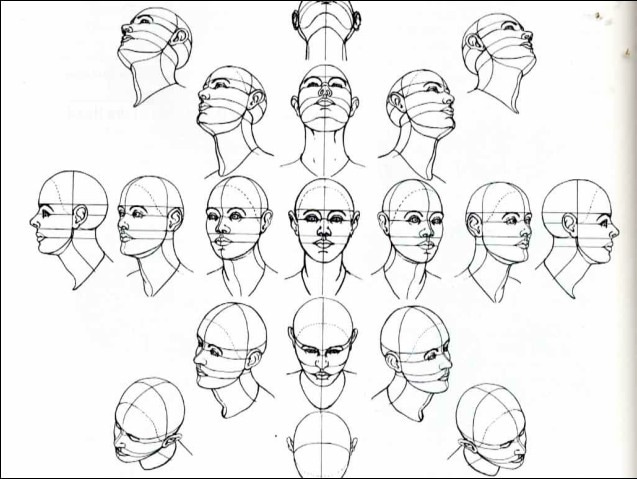
В этом уроке мы будем использовать портрет в качестве примера
Как работают иллюстраторы, когда придумывают персонажей и особенно их лица? Они рисуют несколько ракурсов лица, которые становятся наброском персонажа. Таким образом, у них есть эталон, на который можно смотреть, когда они рисуют новые сюжеты.
При обучении моделей Stable Diffusion на лицах происходит нечто очень похоже, вам нужны данные для обучения хорошего качества. Так что, если вы тренируете что-то на Stable Diffusion, этот метод, вероятно, также улучшит ваши модели.
Шаг 1 – Давайте сгенерируем человека
Есть несколько способов создания портрета, я собираюсь использовать этот способ, вы можете адаптировать его для своих целей. У Ника Сен-Пьера есть хорошая серия твитов, посвященных свету и пленке, а также позированию моделей. Возможно вам будет интересно.
Все промпты в этой статье будут использовать версию MJ V4c, поэтому здесь не будет никаких параметров (–v 4 –q 2 и т. д.), а просто базовые подсказки для Midjourney-бота.
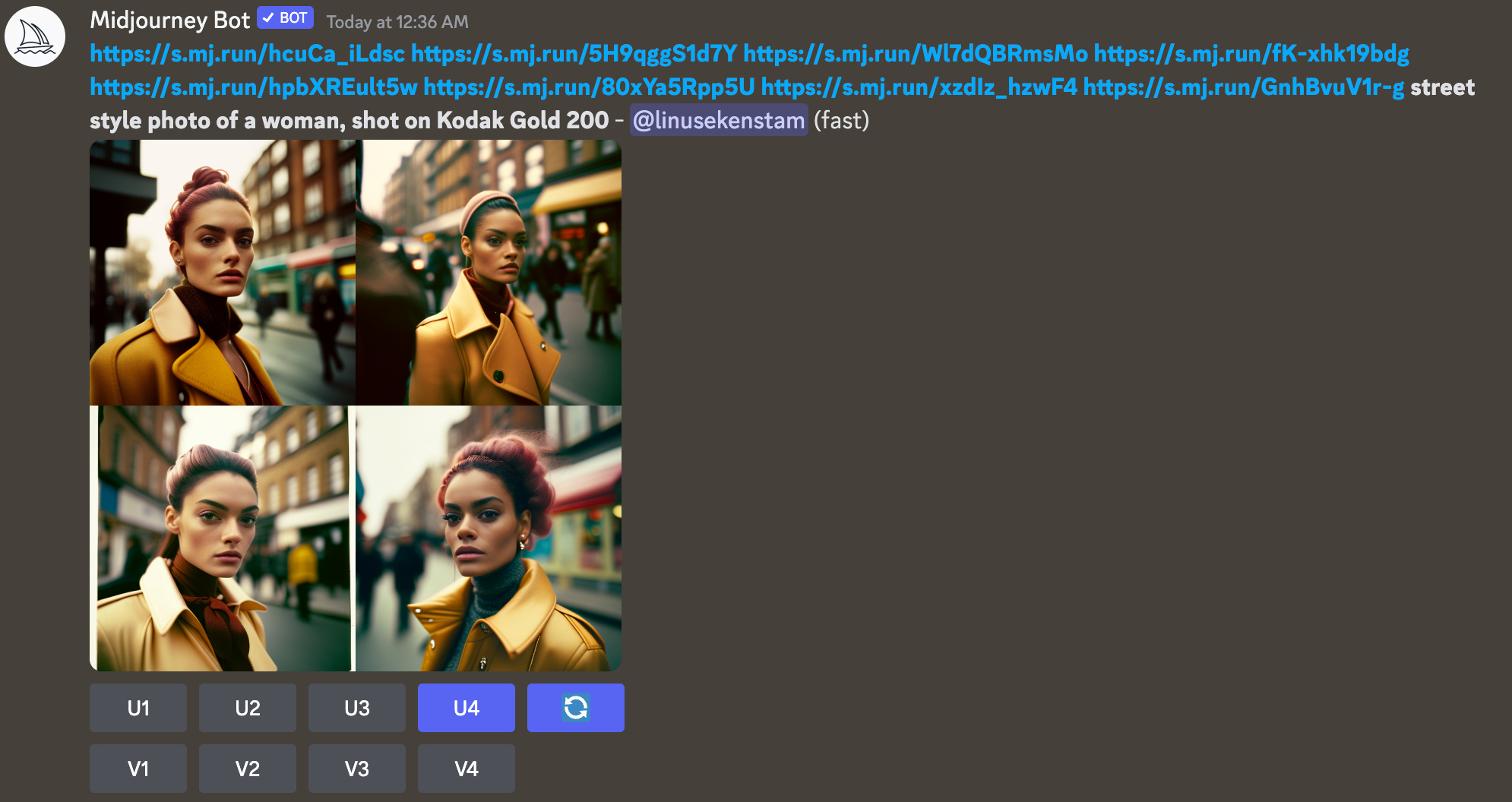
street style photo of a woman, shot on Kodak Gold 200

Если вы хотите другой стиль, вы также можете попробовать этот промпт
studio style photo of a woman light background shot on Kodak Gold 200
Как только у нас сгенерируется первоначальная модель, то нужно выбрать самую подходящую, например номер 3, золотая куртка, розовые волосы. Это наш персонаж нулевого поколения – gen0.
Шаг 2 – Увеличиваем изображение и идем дальше
Итак, теперь, когда мы сделали выбор нужного вариант, увеличили его (Upscale) и убедитесь, что результат выглядит четким, ведь нам не нужны какие-либо серьезные артефакты на изображении. Это изображение проходит нашу визуальную проверку.

Теперь узнаем исходный номер (seed) для этого изображения, просто ответьте через emoji на генерированную картинку, и вы должны получить этот номер.
Узнаем исходный URL-адрес изображения, исходный номер и создаем новую подсказку-промпт.
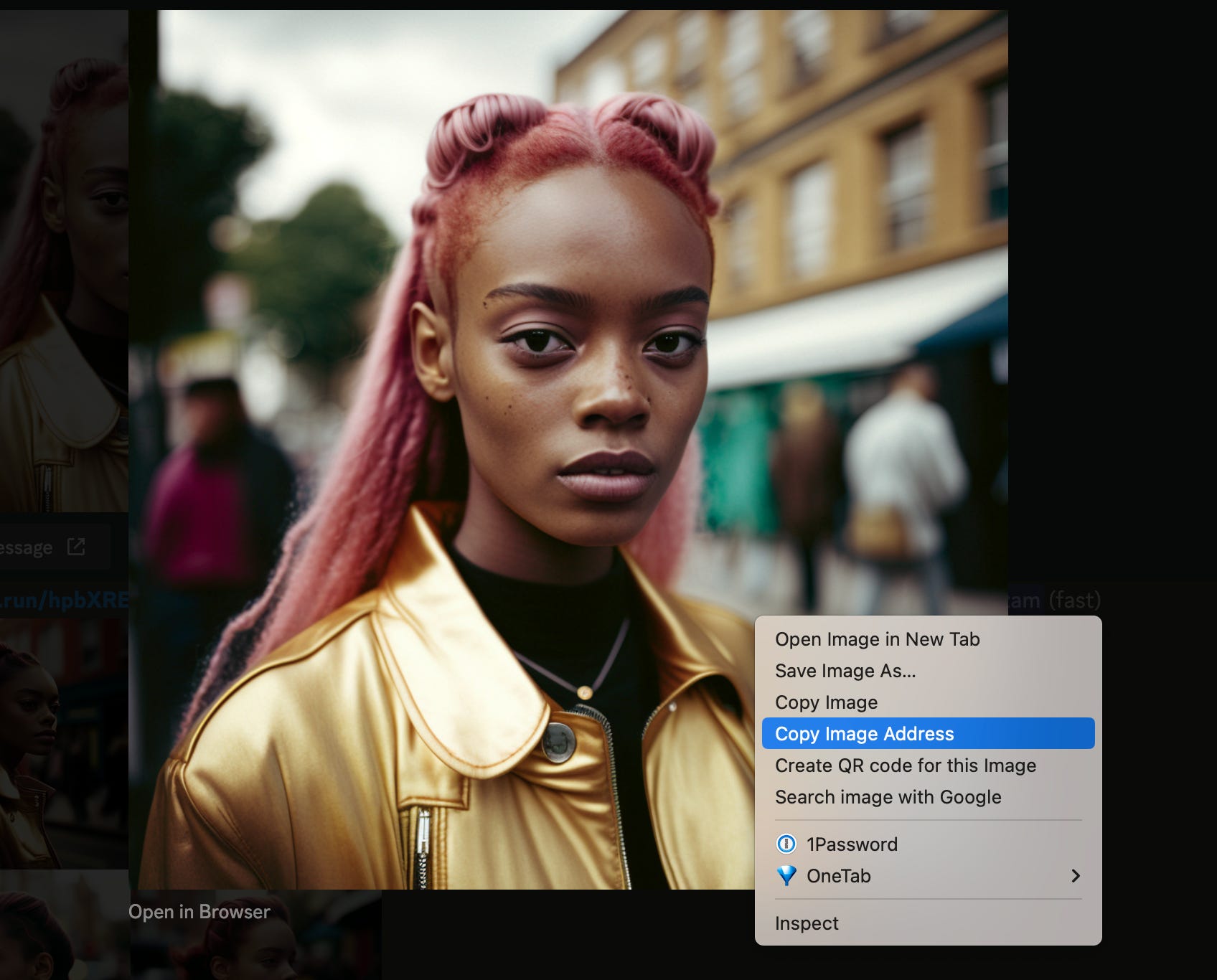
Мы возьмем URL-адрес изображения из Discord – щелкните правой кнопкой мыши и выберите «Копировать адрес изображения».

В этой подсказке мы будем использовать URL-адрес изображения + нашу письменную подсказку, но на этот раз нам нужен вид сбоку side view или profile shot + the initial seed.
<img url> street style photo of a woman, side view, shot on Kodak Gold 200 --seed 15847958

Вы запускаете это столько раз, сколько вам нужно, пока у вас не будет 1-2 изображений левого и правого профиля или вида сбоку. Когда у вас есть те, которые наиболее похожи на исходного человека, увеличим их (Upscale).


На данный момент у нас должно быть как минимум 3 фотографии или больше:
- Вид спереди (1-2 изображения)
- Вид слева (1-2 изображения)
- Вид справа (1-2 изображения)
Давайте возьмем наши изображения и объединим их с новой подсказкой, чтобы получить угол лица сверху. Мы по-прежнему хотим использовать начальный номер. Генерируйте, пока не будете удовлетворены, помните, что мы стремимся получить результаты, максимально приближенные к полученным ранее изображения.
<front> <left-side> <right-side> street style photo of a woman, extreme high-angle closeup, from above, center view, shot on Kodak Gold 200 --seed 158479589

Повторите процесс для нижнего ракурса, помните схему, на которое мы смотрели в начале, мы хотим покрыть как можно больше ракурсов лица.
<front> <left-side> <right-side> <top-view> street style photo of a woman, extreme low-angle, from below, centered view, shot on Kodak Gold 200 --seed 158479589

Шаг 3 – Объедините все это
Итак, на данный момент мы добавляем более 7 изображений в качестве референсных, все изображения, которые мы выбрали, представляют разные ракурсы лица. Скорее всего наша модель выйдет с желтой курткой. Поскольку все наши образы имеют либо желтую, либо золотую куртку. Теперь мы больше не собираемся добавлять номер(–seed) – он нам просто не нужен, и мы больше не хотим начинать с одного и того же паттерна шума.
<front> <left-side-1> <left-side-2> <right-side 1> <right-side 2> <top view> <below view> street style photo of a woman, shot on Kodak Gold 200

Давайте увеличим масштаб 4-го изображения, и я просто помещаю здесь принтскрин Midjourney, чтобы вы могли видеть, что никакой черной магии не происходит. Это то, что мы получаем от Midjourney.
Мы видим, что апскейл немного не соответствует на ухе и серьге. Но помимо этого мы теперь получили последовательную модель без использования начального числа. Вместо этого MJ использует загруженные фотографии в качестве вдохновения. Теперь мы можем считать это нашей новой отправной точкой для создания большего количества «Иоанн». Теперь это наш gen1.

Шаг 4 – Поместите нашу модель в разные сцены
Так что до этого момента мы генерировали изображения 1:1, мы не использовали другие соотношения сторон. На самом деле мы вообще не говорили MJ никаких подробностей.
Итак, давайте попробуем поместить нашу модель в студийную фотосессию. Мы изменим фон, тип кадра, попытаемся заставить ее улыбнуться, а также изменим освещение и тип пленки. Поэтому мы меняем/добавляем множество модификаторов к подсказке, которых не было на референсах. Это может быть сложно, и мы узнаем почему, позже.
<front> <left-side-1> <left-side-2> <right-side 1> <right-side 2> <top view> studio photo, white background, of a woman in a white outfit, ultra wide shot, full body, center view, studio lighting, shot on Fujifilm Pro 400H --ar 16:9



Давайте попробуем что-нибудь еще. Мы можем попробовать надеть какие-нибудь действительно сумасшедшие наряды, вот тот же запрос, но меняющий цвет с розового на желтый.
<front> <left-side-1> <left-side-2> <right-side 1> <right-side 2> <top view> street style photo of a woman in a pink fluffy blowup dress, ultra wide shot, full body, center view, smiling::2 studio lighting, shot on Fujifilm Pro 400H --ar 9:16

Мы можем заменить «Розовое пушистое платье-пуховик» на «Платье LEGO».
Возможно вы спросите, почему “Джоанна” не улыбается, ну, ведь это просто выбранное нами изображение gen0. С небольшой хитростью и несколькими повторными генерациями вы можете заставить ее улыбаться. Добавив приведенное ниже выражение в запрос. Такое ощущение, что она не хочет улыбаться.
smiling::5

Хорошо, мы поняли суть: мы можем изменить подсказку и добавить/вычесть из нее запросы, а иногда нам нужно даже бороться с MJ, и часто все выходит отлично. Давайте попробуем еще кое-что.
Шаг 5 – пробуем другие сцены
Наш персонаж может водить машину? Или ходить в спортзал? Ну, поскольку референсы сделаны из уличной фотографии, мы продолжаем получать фотографии в стиле уличной фотографии. Если мы все таки хотим не уличные сцены, то стоило делать референсы на белом фоне. В любом случае, давайте посмотрим, что мы можем сделать.
Давайте начнем с того, что сделаем ее гонщицей, не указывая есть у нее шлем или нет.

Давайте поместим Джоанну в космическую капсулу. Теперь мы видим обратную сторону использования фотографий уличного стиля в качестве вдохновения. Все наши фоны – улицы. Попытаемся это обойти.
Нам удалось удалить некоторые фоны «улиц», добавив в запрос Interstellar space background.

Где Джоанна действительно сияет, так это в разных необычных уличных сценах.

Можно сгенерировать множество различных стилей с помощью данного инструмента. При этом возможно использовать изображение gen0 и добавлять подсказки с помощью параметра –seed, что позволяет достичь gen1 и новой отправной точки. Таким образом, можно получить несколько комбинаций референсных изображений, которые могут быть использованы для разных целей.




Заключение
Возможно использование техники для создания последовательных персонажей и размещения их в разных средах. Экспериментирование с использованием или без использования числа –seed также возможно.
Предложенная техника напоминает использование подсказок с несколькими кадрами в GPT3. В этом случае ваши изображения для вдохновения действуют как предшественники того, что вы хотите создать, а ваша текстовая подсказка или множественная подсказка действуют как инструкции. В нескольких подсказках вы даете модели набор примеров, а затем даете свои инструкции. Эта техника аналогична, но для Midjourney.
Вывод
Не используйте фотографию в уличном стиле для создания набора изображений для референса. Вместо этого создайте лист более естественных портретов, а затем создайте нейтральные позы и изображения.

Система Midjourney отличается от Stable Diffusion. Для получения согласованных результатов, основанных на одной модели или на ваших селфи, на данный момент рекомендуется использовать пользовательскую модель для Stable Diffusion.
В настоящее время существует множество способов и методов создания последовательных персонажей или предметов, и они появляются почти ежедневно. В будущем, возможно, появится более простой способ, например, легкая предварительно обученная модель или что-то совсем иное.
Оригинал статьи Линуса Экенстама размещен по ссылке
![]()
Notes:
- Диффузионная модель искусственного интеллекта (ДМИИ) – это модель, используемая в компьютерных системах, где искусственный интеллект отвечает за принятие решений на основе математического моделирования процессов диффузии.
В ДМИИ каждый узел или агент в системе представляет частицу, которая передвигается в окружающем пространстве и взаимодействует с другими узлами. Каждый узел имеет некоторые параметры, такие как скорость, направление движения и концентрация вещества, которое он распространяет в окружающем пространстве. ↩
- Stable Diffusion — программное обеспечение, создающее изображения по текстовым описаниям, с открытым исходным кодом. Выпущено в 2022 году. Разработано группой компаний CompVis в Мюнхенском университете. Кроме того, в разработке участвовали Runway, EleutherAI и LAION. Код Stable Diffusion является открытым. ↩
- Discord — кроссплатформенная система мгновенного обмена сообщениями с поддержкой аудио- и видеоконференций, предназначенная для использования различными сообществами по интересам. Наиболее популярна у геймеров и учащихся. Разработчиком является компания Discord Inc. из Сан-Франциско. Discord предлагает бесплатный бот, созданный для MidJourney. Этот бот позволяет загружать текстовые описания и получать готовые изображения в ответ ↩








вот как раз пытаюсь заставить миджорни 5.1 сделать мое лицо похожим) пока не очень выходит, бывают похожие результаты, но при апскейле все рушится..
Просидела пол дня, в итоге студийное фото вообще не похожий персонаж :))